背景
最近因公司项目需要以及后续项目质量保障,准备落地接口自动化框架。我从框架选型、框架设计理念、框架搭建等多方面明确了框架设计思路,并为此总结了0到1落地接口自动化框架的过程,以便日后回顾。
框架选型
常见的自动化框架有unittest、pytest、robotframework和各种二开的自动化框架。
unittest
- unnitest是python自带的一个单元测试框架,,测试人员也经常用来做自动化测试。
- 只要会python的都容易上手,理解成本低,推广容易。
- 属于业内流行的框架,还在不断的迭代,延伸性、可维护性较高、稳定性强。
pytest
- pytest是基于unittest进行封装二开,更加灵活和简洁。
- 功能丰富方便拓展,支持用例异常时重试。
- 支持多条用例并发执行,减少执行时间成本。
robotframework
- robotframework基于关键字驱动的自动化测试框架。
- 该框架可在非代码环境下使用关键字构建可被执行的测试用例。
- 根据excel自动生成自动化测试代码,一定会有非常多的缺陷,框架维护成本特别高。
了解了各种框架特性和优缺点后,综合项目需要满足更具有定制化的功能实现,那么选择unnitest基础框架是比较合适的。
框架设计理念
- 代码可读性。注意文件与模块的关系,用例名和测试用例要关联起来,日志应该有注释输出。
- 灵活性和可维护性。可以实现各种配置来保障可维护性,如基于业务驱动的配置管理、独立的配置文件和基于模块和包进行管理。
- 编码效率。可以前置步骤封装,实现批量构建数据方法。
- 快速定位问题。利用控制变量法并打印用例过程日志、逐行代码打印。
- 易用性。框架的使用要简单好上手,减少理解成本,方便后续在团队中推广起来。
- 框架的运行时间。可以基于unittest和threading进行封装,实现用例多线程执行,提高执行效率。
框架搭建
1.确定基础框架
采用分层设计,下面是目录结构。
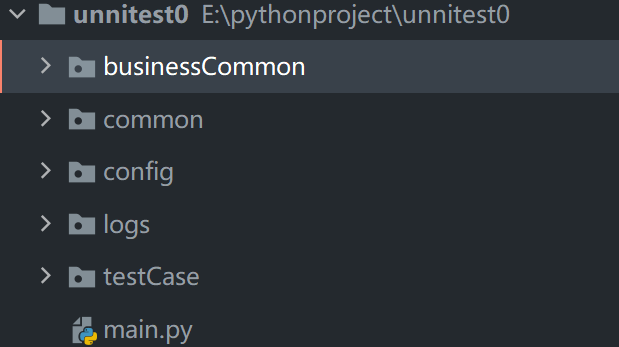
- business:业务层的封装,比方说接口api封装、对应业务加密规则等
- common:通用方法,文件处理、yaml加载、log、通用加密方法等
- config:公共配置,域名、用户身份、相关密钥等
- log:日志文件存储
- testCase:用例集,可以按接口划分一个用例单位,每个用例包含input、major、handle三层
- main:用例执行方法
2.实现common方法
• 实现日志生成方法,满足用例的日志输出和日志存储的方法
def info(text):
"""日志控制台输出的info方法"""
stack = inspect.stack()
formatted_time = datetime.now().strftime('%H:%M:%S:%f')[:-3] # 定义了日志的输出时间
code_path = f"{os.path.basename(stack[1].filename)}:{stack[1].lineno}" # 当前执行文件的绝对路径和执行代码行号
content = f"[INFO]{formatted_time}-{code_path} >> {text}"
print(Fore.LIGHTGREEN_EX + content)
str_time = datetime.now().strftime("%Y%m%d")
with open(file=DIR + '\\logs\\' + f'{str_time}_info.log', mode='a', encoding='utf-8') as f:
f.write(content + '\n')
def case_log_init(func):
@functools.wraps(func) # 解决参数冲突问题
def inner(*args, **kwargs):
class_name = args[0].__class__.__name__ # 获取类名
method_name = func.__name__ # 获取方法名
docstring = inspect.getdoc(func) # 获取方法注释
print(Fore.LIGHTRED_EX + '----------------------------------------------------------------------')
step(f"Method Name:{method_name}, Class Name:{class_name}")
step(f"Test Description:{docstring}")
func(*args, **kwargs)
return inner
def class_case_log(cls):
"""用例的日志装饰器级别"""
for name, method in inspect.getmembers(cls, inspect.isfunction):
if name.startswith('testCase'):
setattr(cls, name, case_log_init(method))
return cls
• 实现通用断言方法,满足接口返回体的断言方法
class CheckPro(unittest.TestCase):
def check_output(self, expected, actual):
"""
接口返回体(dict字典结构)通用校验方法
:param expected: 期望值的协议,协议需要对齐接口文档中的数据结构。
① 接口文档所描述的key 需要对齐到数据结构体中;
② 如果进行动态值校验即校验数据类型, 只需把期望值key的值描述成类型;('order_id': int)
③ 如果进行精确值的校验,把值明确写在数据结构上即可。('order_id': 123)
:param actual:返回体(json需转义为dict)
:return:
"""
self.assertEqual(len(expected.keys()), len(actual.keys()),
msg = f'{actual.keys()} object keys len inconsistent!') # 校验字段长度,是否存在多余字段
for key, value in expected.items():
self.assertIn(key, actual.keys(), msg = f'{key} not in actual') # 校验字段是否存在
if isinstance(value, type): # 校验字段的数据类型(字段为动态值)
self.assertEqual(value, type(actual[key]), msg = f'{key} type inconsistent!')
elif isinstance(value, dict): # 字段为字典结构时
self.check_output(value, actual[key])
elif isinstance(value, list): # 字段为列表结构时
self.assertEqual(len(value), len(actual[key]),
msg = f'{actual.keys()} object items len inconsistent!')
for lst_i in range(len(value)):
if isinstance(value[lst_i], type):
self.assertEqual(value[lst_i], actual[key][lst_i],
msg = f'{value[lst_i]} type inconsistent!')
elif isinstance(value[lst_i], dict):
self.check_output(value[lst_i], actual[key][lst_i])
else:
self.assertEqual(value[lst_i], actual[key][lst_i],
msg = f'{value[lst_i]} value inconsistent!')
else:
self.assertEqual(value, actual[key], msg = f'{key} value inconsistent!') # 校验字段的精确值
• 实现yaml配置读取方法,满足不同维度配置的读取,并且实现环境切换的方法
class YamlRead:
@staticmethod
def env_config():
"""环境变量的读取方式"""
with open(file=f'{DIR}/config/env/{ENVIRON}/config.yml', mode='r', encoding='utf-8') as f:
return yaml.load(f, Loader=yaml.FullLoader)
@staticmethod
def data_config():
with open(file=f'{DIR}/config/data/config.yml', mode='r', encoding='utf-8') as f:
return yaml.load(f, Loader=yaml.FullLoader)
3.main实现
• 用例批量执行方法
run_pattern = 'all' # all 全量测试用例执行 / smoking 冒烟测试执行 / 指定执行文件
if run_pattern == 'all':
pattern = 'test_*.py'
elif run_pattern == 'smoking':
pattern = 'test_major*.py'
else:
pattern = run_pattern + '.py'
suite = unittest.TestLoader().discover('./testCase', pattern=pattern)
• 全局变量的定义
DIR = os.path.dirname(os.path.abspath(__file__))
ENVIRON = 'Offline' # 'Online' -> 线上环境, 'Offline' -> 测试环境
• 报告的生成
result = BeautifulReport(suite)
result.report(filename="report.html", description='测试报告', report_dir='./')
• 控制不同执行维度
4.转换所有主流程测试用例
• 满足用例的前置过程
• 满足用例结果的断言方法
• 遵循用例的编码规范
1)模块的定义,按接口拆分包,按用例级别拆分模块
2)定义方法名 遵循testCase01_remove_key这样的模版
3)通过方法名下的注释实现用例描述,"""XXXX"""
4)所有步骤需要通过日志中的step去声明步骤过程
5)断言方法复用common封装好的能力
def testCase01_major(self):
"""获取首页便签列表 主流程"""
step('【step】前置构建首页便签数据')
create_notes(self.userId1, self.sid1, 1)
url = host + path
step('【step】获取首页便签')
res = self.br.get(url, user_id = self.userId1, sid = self.sid1)
response = res.json()
self.assertEqual(200, res.status_code, msg = '状态码校验失败')
5.business实现
• 封装接口协议的调用方法
@staticmethod
def post(url, json=None, headers=None, sid=None, user_id=None, **kwargs):
info(f'send url: {url}')
info(f'send headers: {headers}')
info(f'send body: {json}')
try:
# 发送 POST 请求
res = requests.post(url, headers = headers, json = json, timeout = 10, **kwargs)
except TimeoutError:
# 如果超时,打印错误信息并抛出 TimeoutError
error('http requests Timeout!')
raise TimeoutError
# 打印接收的状态码和响应体
info(f'recv code: {res.status_code}')
info(f'recv body: {res.text}')
return res
• 封装数据初始化的方法
• 封装数据源的断言方法
• 封装数据的清理方法
6.主流程复用business的能力
• setup实现数据清理方法
• 实现数据初始化方法和断言方法
def setUp(self) -> None:
clear_notes(self.userId1, self.sid1)
def testCase01_major(self):
"""获取首页便签列表 主流程"""
step('【step】前置构建首页便签数据')
create_notes(self.userId1, self.sid1, 1)
7.编写input测试用例
• 通用的测试点实现参数化
• 非通用的测试点直接输出测试用例
class CreateGroupInput(unittest.TestCase):
mustKeys = ['groupId', 'groupName']
@parameterized.expand(mustKeys)
def testCase01_must_key_check(self, key):
8.编写handle测试用例
- 根据具体业务编写测试用例
评论区