背景
在我们团队的项目中,某些HTTP协议接口出现了高并发受阻的问题,由于比较棘手,所以我们将整个项目解耦重构成Kafka消息传递的过程,实现了更高并发的消息处理能力。可见Kafka有效解决了当时的痛点问题。下面我们来聊聊测试人员需要关注Kafka什么细节。
什么是Kafka
Kafka是一个分布式流处理平台,可以处理实时数据流,高效地进行消息传递,包括消息发布和订阅。下面有几个常见概念。
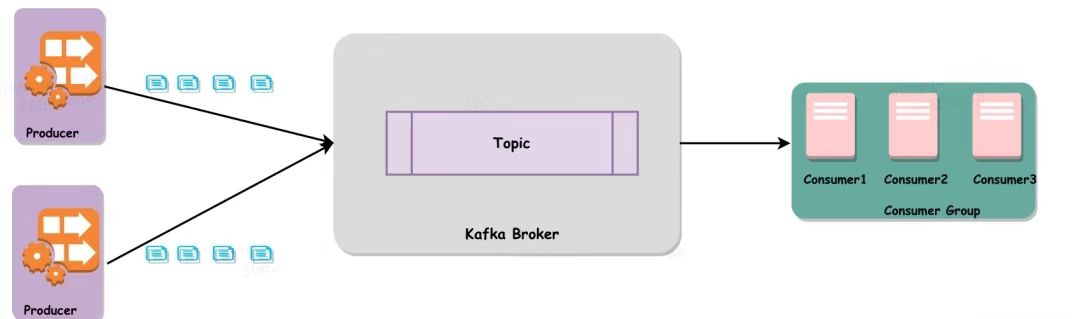
- 生产者(Producer):负责将消息发送到kafka中
- 消费者(Consumer):负责从kafka中拉取消息进行消费
- 主题(Topic):消息的类别
- Broker:Kafka的实例,负责存储和处理消息
消息传递流程:生产者发布一个消息到Kafka的一个Topic ,该Topic的消息存放于的Broker中,消费者订阅这个Topic,然后从Broker中消费消息。
Kafka的作用
- 高吞吐量,低延迟。 Kafka 能够高效地处理大规模的消息流,每秒可以处理几十万条消息,而且消息从生产者(Producer)发送到消费者(Consumer)的延迟时间非常低。
- 持久性。Kafka中会把消息持久化到本地磁盘中。例如微信的聊天记录就是保存在本地,并支持备份恢复。
- 有序性。Kafka消息包通常来说都是一次性的,并按照发送的顺序存储和传递。例如金融交易流水、订单处理流程等。
- 解耦、支持微服务。Kafka 作为中间件,可以有效地解耦各个系统组件,这样组件之间不会直接相互依赖。同时也适合作为微服务之间的消息总线,实现轻量级通信。
Kafka落地场景
-
日志采集。可以解决大量日志传输的问题。日志采集客户端负责日志数据采集,定时写受写入Kafka队列。Kafka负责日志的收集存储和转发。日志处理应用则订阅并消费kafka队列中的日志数据 。

-
应用解耦。例如淘宝用户下单后,订单系统会直接调用库存系统的接口。但如果库存系统出问题了,订单也会生成失败。如果引入了Kafka,那么订单系统作为生产者,将订单信息写入Kafka,直接返回下单成功。而库存系统作为消费者,则从Kafka订阅获取订单消息。这样即使库存系统出问题,订单系统也不会受影响。


- OA离线消息传递。例如用户A使用OA客户端和离线的用户B聊天发消息,用户A在线发送了几条消息,会先传递到Kafka存储,此时会触发其他服务接口来通知用户B有未读消息,用户B打开与A的聊天框,未读消息便会从Kafka一次性全部拉取,实现了离线消息的传递。
Kafka测试策略
我们测试需要做的就是模拟producer到broker,broker到consumer之间的各种故障,模拟场景都是基于业务接口实现的,再验证数据是否完整,有没有数据丢失或者重复。
- 测试对象:被测服务和Kafka的交互场景。
- 测试核心:基于业务场景提供的接口校验消息传递的正确性。
- 测试关注点:
1. 生产者消息的校验。由于Kafka消息传递是一次性的,无法随时查看Kafka中间件的数据,那么生产者发布后的消息需要通过消费者的对外表现校验,也就是基于业务接口校验数据正确性。
2. 消费者消息的校验。同样是基于接口校验对外表现结果,确保消息的完整性。
3. 不同Topic的校验。确保生成者和消费者的topic对齐,不然可能出现生产者发布到topicA,而消费者去订阅topicB,导致消息无法收发。
4. 消息积压的处理。在某些高并发场景,例如用户量突然剧增,消息的消费速度跟不上消息的生成速度,就会出现消息积压。解决方案如下:
1)优化消息者逻辑,修改配置,修改业务逻辑等。
2)增加消费者,扩容消费者的实例。
3)控制生成者的消息发布速度。
评论区